Topher Collins

Analytics Engineer & full-stack AI product builder
dbt, Airflow / Cloud Composer, BigQuery and custom API integrations by day; full-stack, AI-powered products (Flutter, Supabase, LLM pipelines) by night
Background in data science & machine learning - Python, TensorFlow, scikit-learn
Dungeons & Dragons nerd, founder of DnDwithToph.com
History Check
View My LinkedIn
View My Articles on Medium
Dungeons & Dragons Race Classification > Go to project
This project involves using Scikit-learn and Pandas to create a machine learning model for a multiple classification problem aimed at predicting the race of a Dungeons & Dragons character based on their ability scores and general features.
Problem Definition
This project aims to predict the race of Dungeons & Dragons characters based on their ability scores and other features. The goal is to create a machine learning model that can accurately classify the race of a character.
Data
The original dataset was obtained from Kaggle, provided by Andrew Abeles: DND Character Stats Dataset.
Evaluation
Aim To achieve a classification accuracy that matches or surpasses 51.8%, the model accuracy from Andrew Abeles’s project (KNN tuned model).
Features
The dataset contains 10,000 samples, each with 9 input features and 1 target feature.
Input Features:
- Height (inches)
- Weight (lbs)
- Speed (ft.)
- Strength
- Dexterity
- Constitution
- Wisdom
- Intelligence
- Charisma
Target Variable:
- Race (dragonborn, dwarf, elf, gnome, half-elf, half-orc, halfling, human, tiefling)
Exploratory Data Analysis
Correlation matrix to visualize the relationships between features.
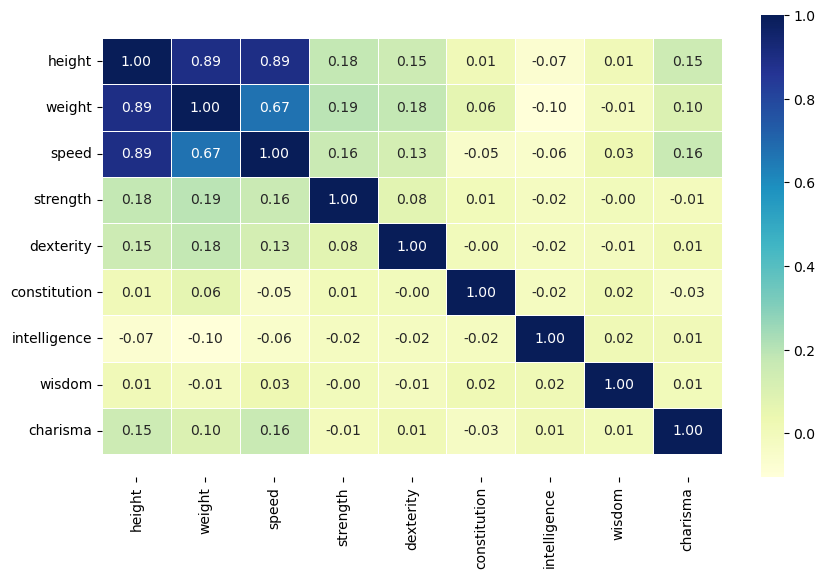
The correlation heatmap showed strong relationships between height, weight, and speed, indicating their significance in predicting the character’s race.
Further comparison of height and weight features using a scatter plot.
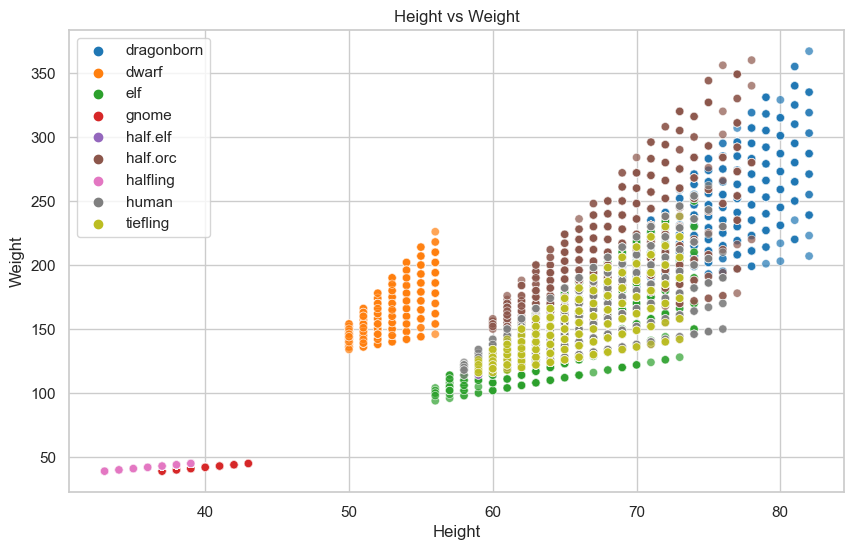
The scatter plot revealed trends in three clear groups/clusters of character sizes: small, medium, and large.
Modelling
-
Data Preprocessing: The dataset was loaded into a Pandas DataFrame. There were no missing values.
-
Exploratory Data Analysis (EDA): Data visualization was performed to understand feature correlations and distributions.
-
Model Selection: Several machine learning models were evaluated, including Support Vector Classifier (SVC), K-Nearest Neighbors (KNN), Random Forest Classifier, AdaBoost Classifier, and Logistic Regression.
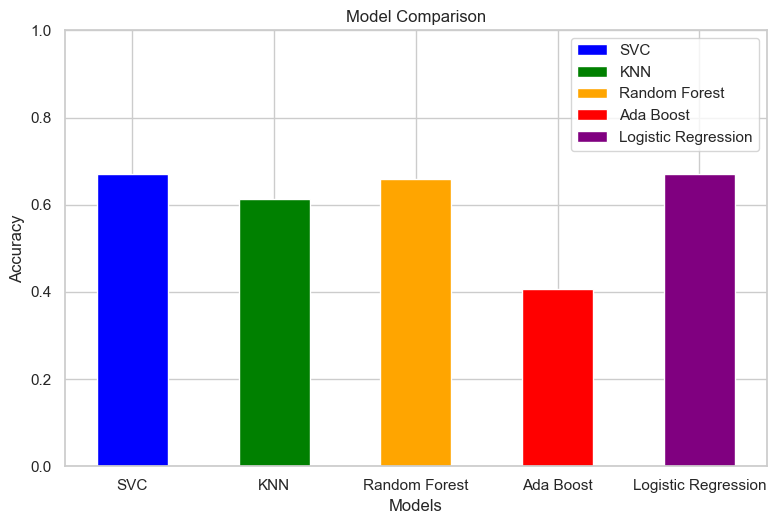
Among the baseline comparison of models, Random Forest and Logistic Regression demonstrated the highest accuracy scores.
- Model Evaluation: Initial model scores were computed and compared. Random Forest, Logistic Regression and SVC performed similarly.
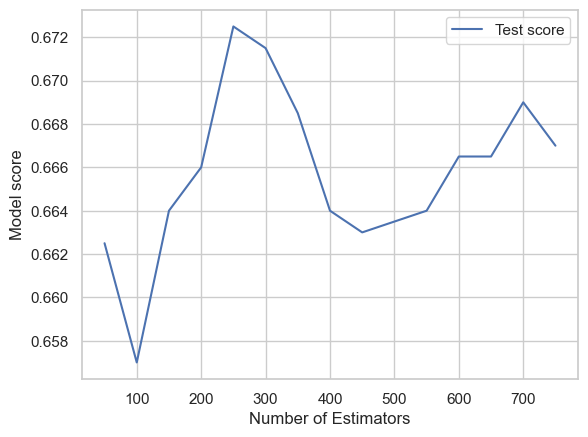 Fine-tuning Random Forest Classifier against n_estimators.
Fine-tuning Random Forest Classifier against n_estimators.
- Hyperparameter Tuning:
- Random Forest: Randomized and Grid Search CV were used to optimize hyperparameters.
- Logistic Regression: Randomized and Grid Search CV were used to optimize hyperparameters.
-
Model Comparison: The best Random Forest model was selected based on the hyperparameters obtained from Grid Search CV.
- Cross-Validation: Using the best parameters obtained from the fine-tuning process, we created a final Random Forest model and evaluated its performance using cross-validation for accuracy, precision, recall, and F1-score.
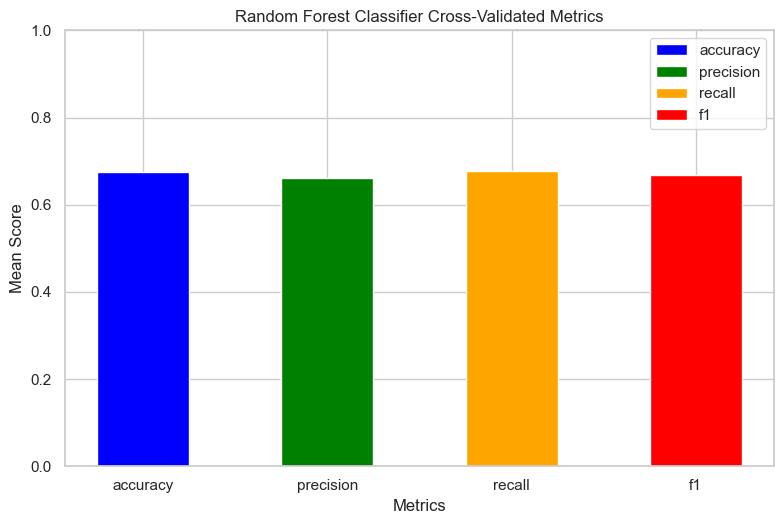
The mean scores of accuracy, precision, recall, and F1-score were as follows:
Accuracy: 0.6748 Precision: 0.6609 Recall: 0.6762 F1-score: 0.6690
Conclusion
The project involved building and tuning a machine learning model to predict the race of a DND character based on their ability scores and general features. The Random Forest model achieved an accuracy of around 67.25% after hyperparameter tuning and cross-validation, improving upon the previous accuracy of 51.8% found in the orignal KNN model from the Dataset.